OpenHuman 和普通聊天机器人最大的区别是个人上下文系统
如果只看聊天窗口,很多 AI 产品都很像:输入问题,等待回答,复制结果。OpenHuman 想解决的不是“再做一个聊天机器人”,而是让 AI 在你的个人上下文里长期工作。这个定位决定了它和普通聊天工具的差异。
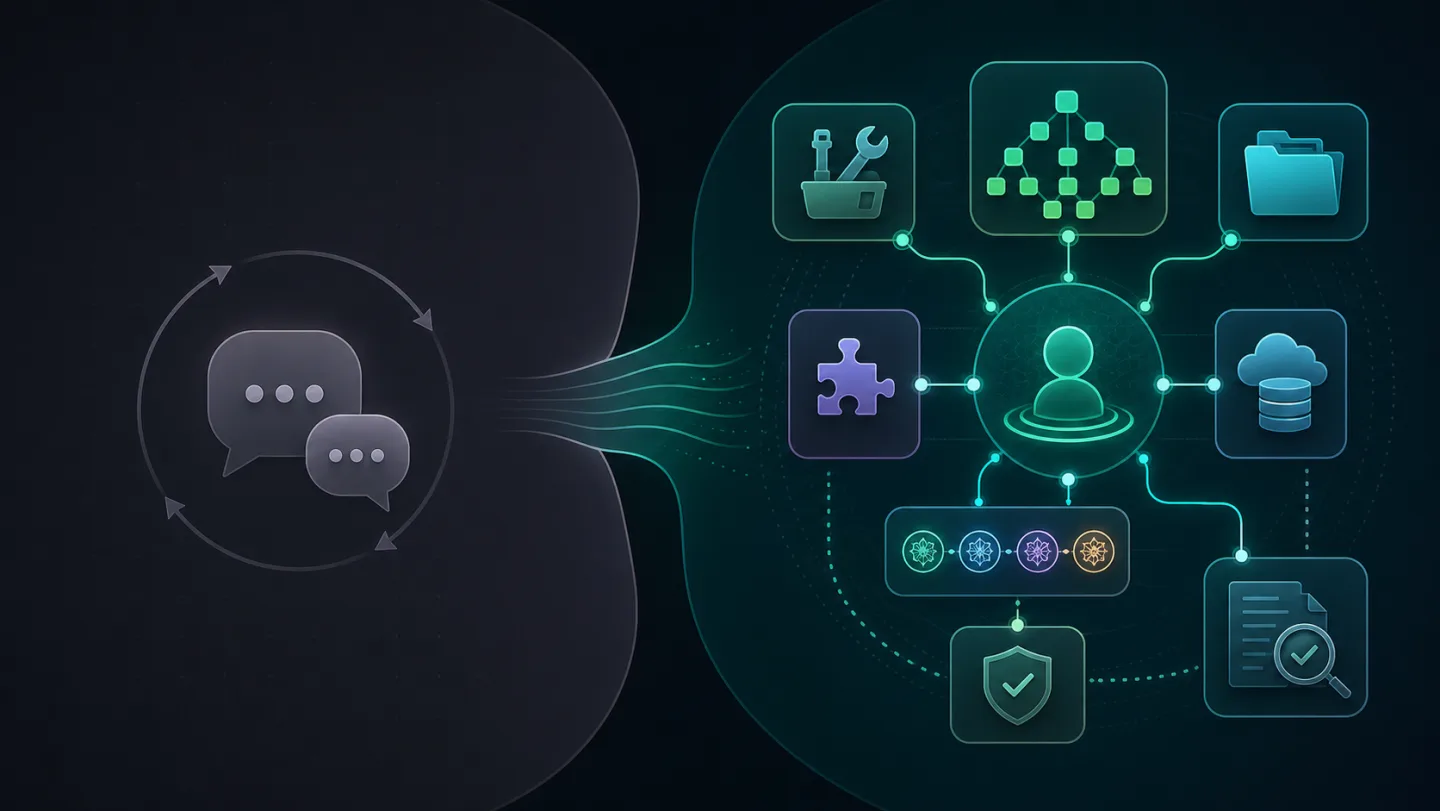
图示:OpenHuman 的差异不在聊天框外观,而在工具、记忆、来源回看和模型路由组成的上下文系统。
理解这个差异,可以从五个角度入手:桌面入口、长期记忆、工具集成、本地优先和压缩后的模型调用。
桌面入口让它更接近日常工作台
普通聊天机器人通常是网页或 App 里的对话框,任务边界由用户每次输入决定。OpenHuman 则强调桌面 GUI 和本地运行环境,目标是让用户在一个工作台里连接模型、记忆、工具和集成。
这不是视觉包装问题。桌面入口意味着它可以更自然地承载本地文件、系统权限、Obsidian Vault、通知、语音和后台流程。对需要长期处理个人资料的人来说,入口形态会影响使用方式。
长期记忆不是保存聊天记录
很多聊天产品的记忆仍然围绕“我在对话里说过什么”。OpenHuman 更强调从日历、邮箱、文档、项目和聊天等来源提炼可复用上下文,再把它组织成 Memory Tree 和 Markdown 知识库。
这让问题从“模型还记不记得上一轮对话”变成“我的工作资料有没有被整理成可检查的长期记忆”。后者更难,但也更接近个人 AI 助手真正有价值的地方。
集成不是插件数量比赛
OpenHuman 公开资料提到 118+ OAuth 集成。这个数字很容易被当成卖点,但真正重要的是连接器如何进入记忆和工具调用流程。一个集成如果只是把数据拉出来展示,价值有限;如果它能成为可追溯的上下文来源,并被权限边界约束,价值才会放大。
中文用户评估集成时,应该关注三件事:授权范围是否清楚,同步后的摘要是否能检查,AI 是否能说明它用到了哪些来源。
本地优先决定隐私边界
个人 AI 助手会接触大量敏感信息。OpenHuman 的本地知识库、SQLite、Obsidian Vault 和可选本地模型,是它区别于纯云端聊天产品的重要部分。它并不意味着所有功能都永远离线,但意味着用户可以把一部分关键上下文留在自己设备上,并围绕本地文件建立检查习惯。
对中文用户来说,本地优先还关系到网络稳定性、模型供应商选择、数据合规和长期迁移。如果你只是偶尔问答,这些问题不明显;如果你想让 AI 参与真实工作流,它们会变成核心问题。
TokenJuice 说明它在认真处理上下文成本
公开资料把 TokenJuice 描述为调用模型前的压缩层。这个方向很关键,因为个人上下文系统会产生大量文本:网页、邮件、会议、日志、仓库和聊天记录。如果每次都原样塞给大模型,成本、延迟和噪音都会迅速失控。
压缩层的目标不是让信息变少,而是让模型看到更干净、更便宜、更可控的上下文。未来评估 OpenHuman 时,TokenJuice 的实际质量会直接影响长期使用体验。
谁更适合先试 OpenHuman
如果你只是偶尔问几个通用问题,普通聊天机器人已经足够。如果你希望 AI 能理解你的项目、资料、日程和偏好,并且愿意花时间维护记忆边界,OpenHuman 才更值得投入。
它目前仍是快速变化中的开源项目,所以最好的试用方式不是盲目全量迁移,而是选择一个小项目跑通闭环:连接一个数据源,等待同步,检查 Memory Tree,用一个真实问题验证,再决定是否扩大范围。
下一步阅读
可以先读本站的 OpenHuman 是什么、OpenHuman 与其他 Agent 的对比 和 隐私与安全边界。如果你关心技术结构,继续看 开发者架构。
资料来源:本文基于 OpenHuman 官网、tinyhumansai/openhuman GitHub README、OpenHuman GitBook 以及公开独立评测资料做中文原创整理。本文不复制第三方文章正文。