OpenHuman TokenJuice 是什么:为什么个人 AI 需要上下文压缩层
OpenHuman 想处理的不只是几轮聊天,而是邮件、日历、网页、代码仓库、会议记录、Slack/Notion/GitHub 等长期工作流数据。问题在于,这些数据如果原样进入模型上下文,会迅速变得又贵又慢,还会让真正重要的信息被日志、HTML、重复字段和无关片段淹没。
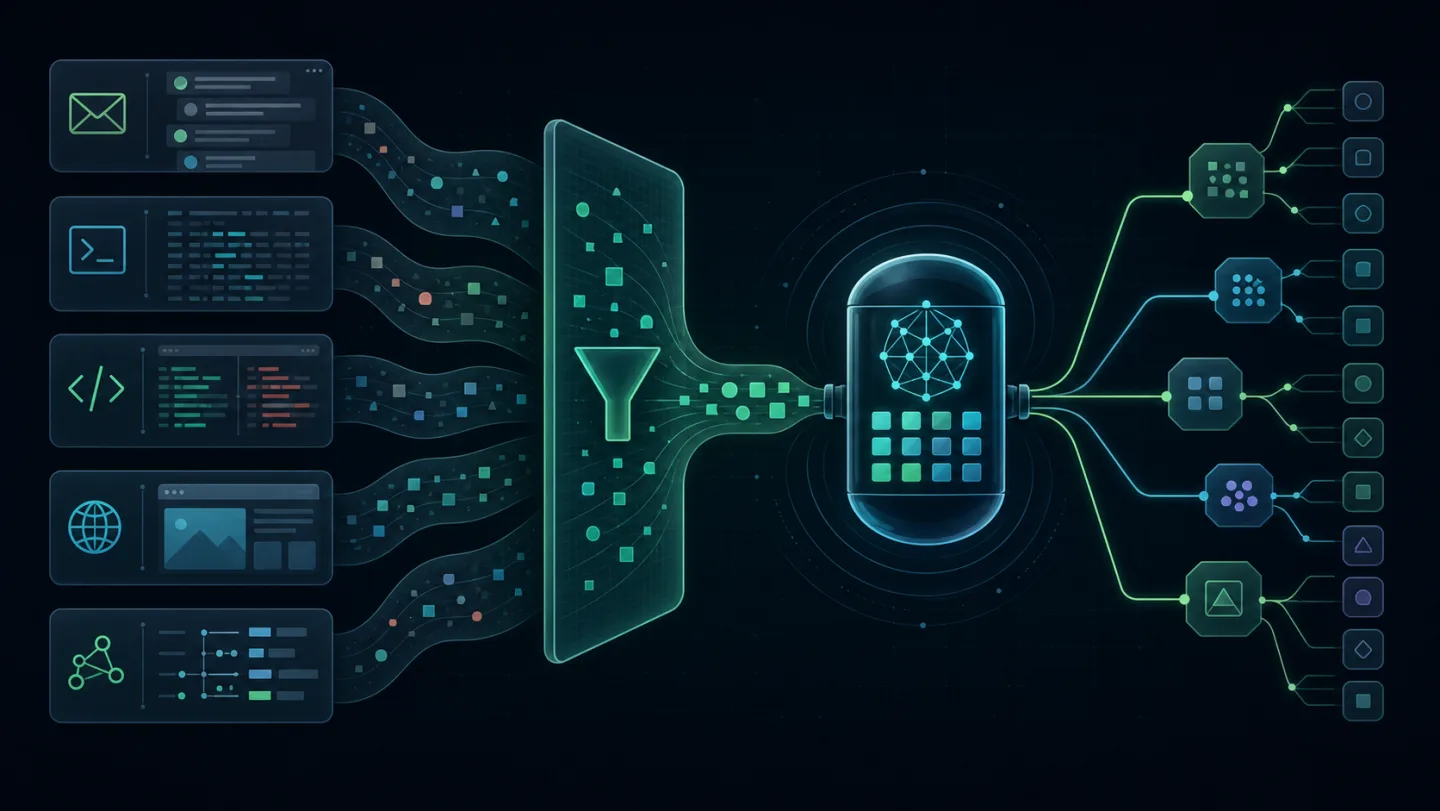
图示:TokenJuice 的价值在于把邮件、日志、网页和代码差异等高噪声输入,先压缩成更适合模型和长期记忆处理的上下文。
TokenJuice 就是 OpenHuman 用来处理这个问题的压缩层。它的目标不是把内容随便截短,而是在工具输出进入模型之前先做清理、规整和减噪,让模型看到更接近“任务相关上下文”的材料。
TokenJuice 解决的是工具输出膨胀
个人 AI 的上下文压力通常不是来自用户那一句提示词,而是来自工具调用结果。一个网页抓取结果可能包含大量导航、脚本残留和重复链接;一段构建日志可能有成百上千行重复 warning;一个邮件线程可能夹杂签名、引用历史和营销页脚;一个代码仓库命令可能输出很多和当前任务无关的文件。
这些内容直接塞进模型,会产生三个问题。第一是成本上升,因为更多 token 意味着更多调用费用。第二是延迟变高,因为模型要处理更长上下文。第三是质量下降,因为噪声会稀释日期、联系人、决策、错误原因和待办这类真正关键的信息。
它不是普通摘要,而是进入模型前的规则层
OpenHuman 上游文档把 TokenJuice 描述为集成在工具执行路径里的规则覆盖层。它会在工具结果进入 LLM context 之前运行,用规则匹配不同工具或命令输出,再采取截断、去重、折叠空白、删除匹配噪声、压缩章节等策略。
这和“让大模型再总结一遍”不完全一样。TokenJuice 更靠近输入管线,先把低价值结构减掉,再把更干净的上下文交给后续模型或记忆流程。这样做的好处是,昂贵模型不必为明显重复或格式噪声付费。
三层规则让个人和项目都能覆盖默认行为
上游文档提到 TokenJuice 规则可以分成三层:内置规则、用户规则和项目规则。内置规则覆盖常见工具输出,例如 git、npm、cargo、docker、kubectl、ls 等;用户规则适合放个人全局偏好;项目规则则适合放在仓库内,让团队共享同一套压缩约定。
这个设计对开发者很重要。不同项目的“噪声”和“信号”并不一样。对一个前端项目来说,构建日志里的某些 warning 可能可以折叠;对一个基础设施项目来说,同样的 warning 可能就是关键线索。可覆盖规则让 TokenJuice 不必把所有场景都写死。
为什么它会影响 Memory Tree
OpenHuman 的 Memory Tree 要长期吸收来自集成和工具的数据。如果每次 Gmail、GitHub、Slack 或网页抓取都把原始内容完整交给模型,记忆构建成本会很快失控。TokenJuice 的作用是在生成摘要和进入记忆之前先控制输入质量。
这会直接影响长期记忆的可靠性。好的压缩应该保留实体、时间、来源、决策、待办、金额、错误和异常;不好的压缩则可能把关键证据删掉,只留下看似整洁但不可验证的摘要。因此,TokenJuice 的价值不只是“省钱”,而是让 Memory Tree 更有机会在长期运行中保持可维护。
中文用户应该怎么判断压缩是否可靠
普通用户不需要一开始就写规则,但应该学会检查结果。最简单的方法是对同一个任务做来源回看:让 OpenHuman 给出结论后,检查它是否能说明来源、时间和关键依据。如果答案变短了但证据消失了,就不是好的压缩。
你还可以专门测试几类容易出错的信息:日期、联系人、金额、会议结论、权限说明、错误堆栈和待办归属。如果这些信息经常丢失,就应该缩小任务范围、回看原始资料,或者在后续版本里调整规则,而不是盲目相信压缩后的上下文。
TokenJuice 与模型路由要一起看
TokenJuice 负责让输入更干净,模型路由负责把任务交给合适模型。两者放在一起,才构成个人 AI 的成本控制体系。简单摘要可以交给便宜快速的模型,复杂推理交给更强模型,敏感内容尽量走本地或更受控路径,而进入这些模型之前的上下文都应该先被整理成更高信噪比的材料。
如果没有压缩层,模型路由容易被长输入拖垮;如果没有模型路由,压缩后的上下文也未必交给了最合适的模型。因此,理解 OpenHuman 的成本和延迟,不应该只看“支持哪些模型”,还要看它如何处理模型之前的输入。
开发者可以关注哪些位置
上游文档提到 TokenJuice 的实现位于 src/openhuman/tokenjuice/,包括分类、压缩、规则编译和工具集成相关逻辑。它还支持在用户配置目录或项目 .tokenjuice/rules/ 中放 JSON 规则,用于全局或项目级覆盖。
如果你要参与开发或排查压缩问题,重点不是先追求最高压缩率,而是建立可复现样本:同一段工具输出在压缩前后保留了哪些事实,删除了哪些噪声,最终模型回答是否更准确。对个人 AI 来说,压缩率只是指标之一,事实保真和来源可追溯同样重要。
下一步阅读
如果你想先理解概念,可以继续读本站的 TokenJuice 压缩、模型路由 和 Memory Tree 长期记忆。如果你更关心落地风险,可以看 OpenHuman 安全边界:安装脚本、OAuth 授权和本地记忆应该怎么检查。
资料来源:本文基于 tinyhumansai/openhuman GitHub README、OpenHuman Token Compression 上游文档、本站同步的 docs-upstream/features/token-compression.md 与公开独立资料做中文原创整理。涉及具体路径、规则格式和运行参数时,请以当前上游仓库和实际版本为准。